
프로젝트를 진행하면서 RAG를 구현하게 되었다. 어떻게 RAG를 구현하였는지 그 구현기를 포스팅하겠다.
참고로 시행착오를 엄청 겪으면서 구현했기 때문에 조금 길다.
RAG란 무엇인가?
LLM은 기존에 가지고 있는 지식만을 가지고 사용자의 질문에 답변할 수 밖에 없는데, 만약 사용자의 질문이 LLM이 학습한 지식의 범위를 벗어난다면 이에 답하지 못하거나 할루시네이션이 발생할 가능성이 크다.
외부의 지식과 사용자의 질문을 같이 LLM에게 제공하여 답변할수 있도록 하는 방법이 바로 RAG이다.
왜 RAG를 구현했나?
내 프로젝트는 일기를 기반으로 하는 프로젝트였다. 내가 구현하고 싶었던 방식은 사용자의 질문에 가장 알맞은 일기를 검색해서 사용자에게 건네주는 방식인데, 단순한 키워드 검색이나 벡터 검색은 이를 구현하기에는 부족했다.
예를 들어 "민수와 함께 여행을 떠난 날" 이라고 검색했을 때, 사용자가 검색되길 원하는 일기에는 "민수와 같이 공항에 도착해서 비행기를 탔다" 라고만 적혀있다면 이 일기를 사용자에게 어떻게 보여줄 수 있을까?
이는 LLM을 이용해서 의미를 파악해야만 적절한 일기를 가져올 수 있을 것이라 생각하고 구현에 들어갔다.
그러면 이렇게 생각할 수도 있겠다. 그냥 일기 전체 다 LLM에게 먹이고 질문을 통해서 적절한 일기만 가져오라고 하면 안되나?
물론 이렇게 구현하면 정확도는 가장 높겠지만 토큰 수도 장난아닐거고 시간도 엄청나게 오래 걸려서 적절한 방법이 아니다.
그래서 일기 중 관련이 있을것같은 것들만 추려서 LLM에게 질의해주는 과정이 필요하다. 이를 위해서 일기를 임베딩하여 벡터 DB에 저장해두고 검색어도 벡터화하여 벡터 검색을 수행하여 필터링을 거치고, 마지막까지 남은 일기들만 LLM에게 던진다.
LLM에게 관련이 있는 일기만 true를 달아서 반환해달라고 요청하고, 응답에서 true가 달려있는 일기만 필터링해서 사용자에게 보여주면 끝!! 이었지만 사실 엄청난 시행착오가 들어가 있었다...
준비물
LLM API 또는 로컬 LLM 모델과 임베딩 모델, Vector DB가 필요하다
나는 LLM으로 AWS Bedrock을 사용했고, Vector DB로는 Qdrant를 사용했다.
임베딩 모델로는 허깅페이스에서intfloat/multilingual-e5-large Dongjin-kr/ko-reranker 를 사용했다.
임베딩 모델들은 각 모델별로 성능과 용도가 상이하니 프로젝트에 맞는 모델을 찾는 것이 중요하다
NestJS에서 RAG 구현해보기
첫번째 시도 : 일기를 통째로 임베딩
맨 처음에는 vector DB의 성능만 믿고 일기를 통째로 임베딩하여 저장해두었다. 그냥 막연히 유사한 의미를 코사인 유사도로 잘 찾아주겠지 ~ 싶었는데 기술이 그렇게 쉽게 동작하질 않더라
유사도가 너무 떨어져서 도저히 써먹질 못했었다.
두번째 시도 : 일기를 문장 단위로 청킹하여 임베딩
멘토님께 조언을 받아서 청킹해서 임베딩하기로 했다. 찾아보니 python에 한국어 문장 분리기 라이브러리를 만들어 두신 분이 계셨다. 그런데 라이브러리 버전이 잘 맞질 않아서 사용할 때 엄청 애를 먹었다ㅠㅠ
결국 어찌저찌 만들어서 도커 컨테이너로 만들어서 flask로 띄우고, nestjs에서 axios로 요청을 보내 응답을 받는 것에 성공했다.
본 서버에서는 청킹된 문장을 임베딩하여 저장만 하면 끝이었다.
from flask import Flask, request, jsonify
import kss
app = Flask(__name__)
@app.route('/split', methods=['POST'])
def split_sentences():
text = request.json['text']
sentences = kss.split_sentences(text)
return jsonify({"sentences": sentences})
if __name__ == "__main__":
app.run(host='0.0.0.0', port=5006)요건 문장 분리기 코드인데, 라이브러리 버전 때문에 잘 동작하질 않는다.. 내 docker hub에 올려두었으니 이걸 쓰자

사용 방법은 그냥 다음 명령어를 입력해서 pull 받고 실행시키면 끝이다.
docker pull gooch1744/sentence-parser:latestarm64 버전에서는 태그만 바꿔주자
docker pull gooch1744/sentence-parser:arm64
nestJS에서는 다음과 같이 코드를 작성했다.
/**
* 텍스트를 받아 문장 단위로 파싱하여 반환합니다
*/
async parsingText(text: string) {
const url = this.configService.get('PARSER_MODEL_URL');
const response = await axios.post(url, { text: text });
return response.data.sentences;
}PARSER_MODEL_URL은 파싱 서버를 띄워놓은 주소로 지정해두고, axios를 이용해 요청을 보내면 된다.
리턴하는 값은 파싱된 문장의 배열들이다.
파싱된 문장들은 vector DB에 각자 임베딩하여 저장해두면 된다. 이 프로젝트에서는 qdrant를 사용했는데, 사용법은 이전 포스팅에 적어두었으니 참고하길 바란다.
/**
* 문장을 qdrant에 저장합니다
*/
private async saveSentencesToQdrant(
sentences: string[],
author: Member,
date: LocalDate,
diaryId: number,
) {
for (const sentence of sentences) {
const payload = {
diary_id: diaryId,
memberId: author.id,
sentence: sentence,
date: date,
};
//임베딩 모델에게 전달하여 벡터값 받기
const vector = await this.embedService.embed_passage(sentence);
await this.qdrantService.upsertVector(
this.collection,
uuidv4(),
vector,
payload,
);
}
}
// qrantService
async upsertVector(
collection: string,
id: string,
vector: number[],
payload: any,
) {
await this.client.upsert(collection, {
wait: true,
points: [{ id, vector, payload }],
});
}payload에는 검색 시에 문장과 같이 이 문장이 원래 들어있던 일기의 id와 일기의 작성자 id가 같이 들어가있도록 해두었다.
그래야 검색을 시도한 사용자의 id를 통해 벡터 DB에서 검색을 수행할 것 아닌가?
일기의 id는 검색해서 가져온 문서에서 꺼낸 다음 RDB에서 해당 일기를 다시 검색하여 원문을 사용자에게 돌려주기 위함이다.
여기까지 구현하고 나니, 연관된 문장이 잘 나오기는 했다. 그런데 여전히 연관성이 없어보이는 문장들도 여럿 뽑혀서 LLM에게 같이 넘어갔고, 이는 곧 LLM의 토큰 수 증가와 응답 시간의 증가로 이어졌다. 여기서 문장을 좀 더 필터링할 필요가 있었다.
세 번째 시도 : rerank로 추가 필터링
사실 두번째 시도에서 사용한 임베딩 모델은 듀얼 인코더이다. 듀얼 인코더는 입력을 query와 passage로 각각 따로 나누어 임베딩한 뒤, 두 벡터의 유사도를 점수로 계산하는 구조이다. 듀얼 인코더 모델 코드는 아래 펼치기
from flask import Flask, request, jsonify
from sentence_transformers import SentenceTransformer
app = Flask(__name__)
model = SentenceTransformer("intfloat/multilingual-e5-large")
@app.route("/embed", methods=["POST"])
def embed():
data = request.get_json()
input_text = data["text"]
prefix = data.get("prefix", "query:") # 기본값: query
print(f"{prefix} : {input_text}")
embedding = model.encode(
f"{prefix} {input_text}", normalize_embeddings=True)
return jsonify({"embedding": embedding.tolist()})
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5001)하지만 듀얼 인코더로 문서 간의 유사도가 정확하다고는 할 수가 없다. 다만 속도가 굉장히 빠르기에 1단계에서 사용되는 것일 뿐이다. 컴퓨터의 세상에서는 뭐든 트레이드 오프라는것을 상기하자.
듀얼 인코더를 통해 1차로 필터링된 문서들을 크로스 인코더로 한번 더 필터링했다.
크로스 인코더는 질의와 문서를 하나의 입력으로 합쳐 두 문서 간의 상호작용을 직접 보게 만드는 임베딩 모델이다. 듀얼 인코더에 비해 정밀도가 높지만, 시간 비용이 높다. 따라서 "처음부터 크로스 인코더를 사용하지 되지 않냐?" 는 트레이드 오프때문에 막히는 것이다.
크로스 인코더까지 사용해서 2차 필터링을 하는 과정을 그림으로 그리면 다음과 같다
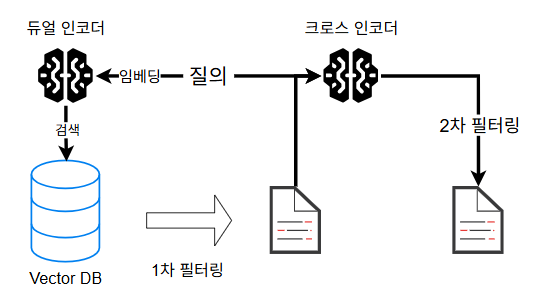
2차 필터링을 통해 각 문서가 rerank되면, 각 문서의 유사도/순위 순대로 잘라서 LLM에게 제공해주면 된다.
필터링을 거치는 과정을 코드로 나타내면 다음과 같다
const vector = await this.embedService.embed_query(query);
const hits = await this.qdrantService.searchVectorByMember(
this.collection,
vector,
memberId.toString(),
100,
);1차 필터링을 위해 듀얼 인코더에 query를 임베딩하여 vector 변수에 담는다. 이후 vector + 문서 payload의 memberId를 기반으로 검색된 문서들 중 top-k 문서만 반환하는 searchVectorByMember를 사용해서 문서 100개만 hits에 저장한다.
const candidates = hits
.filter((hit) => hit?.payload?.sentence)
.map((hit) => ({
id: hit.id,
text: hit!.payload!.sentence,
}));
// rerank 요청
const rerankUrl = this.configService.get('RERANK_MODEL_URL');
const rerankRes = await axios.post(rerankUrl, {
query,
candidates: candidates.map((c) => ({
id: c.id,
text: c.text,
})),
});이후 hits의 정보들과 query를 크로스 인코더 모델에게 rarank 요청으로 보낸다. 이로서 질의와 문서들이 한쌍씩 하나하나 같이 임베딩되어 점수가 매겨진 후, 서버로 다시 전송될 것이다.
크로스 인코더 모델 코드는 아래 펼치기
from flask import Flask, request, jsonify
from sentence_transformers import CrossEncoder
import numpy as np
import logging
# 로깅 설정
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
app = Flask(__name__)
# Cross-Encoder 모델 로드
model = CrossEncoder('Dongjin-kr/ko-reranker')
@app.route("/rerank", methods=["POST"])
def rerank():
data = request.get_json()
query = data["query"]
candidates = data["candidates"] # [{id, text}, ...]
logger.info(f"=== 새로운 Cross-Encoder Reranking 요청 ===")
logger.info(f"쿼리: {query}")
logger.info(f"후보 문서 수: {len(candidates)}")
logger.info(f"후보 문서: {candidates}")
for i, candidate in enumerate(candidates, 1):
logger.info(f"후보 {i}: id={candidate['id']} / text={candidate['text']}")
logger.info("=" * 50)
# Cross-Encoder는 (query, candidate_text) 쌍으로 입력을 받음
candidate_texts = [c["text"] for c in candidates]
model_inputs = [[query, text] for text in candidate_texts]
# 모델을 통해 점수 계산
scores = model.predict(model_inputs)
logger.info("=== 계산된 점수 ===")
for i, (candidate, score) in enumerate(zip(candidates, scores)):
logger.info(
f"후보 {i+1} 점수: {score:.4f} - id={candidate['id']} / text={candidate['text']}")
logger.info("=" * 50)
reranked = sorted(
[
{
"id": c["id"],
"text": c["text"],
"score": float(s)
}
for c, s in zip(candidates, scores)
],
key=lambda x: x["score"], reverse=True
)
logger.info("=== 최종 Reranking 결과 ===")
for i, item in enumerate(reranked, 1):
logger.info(
f"순위 {i}: {item['score']:.4f} - id={item['id']} / text={item['text']}")
logger.info("=" * 50)
return jsonify(reranked)
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5002)마무리
마무리로는 응답을 통해 받은 reranked 배열을 텍스트와 RDB의 id만 남겨서 질의와 같이 LLM에게 제공해주기만 하면 된다.
나는 각 문장마다 질의와 연관되는지 true와 false를 달아달라고 한 다음 true가 붙은 문장의 RDB id만 검색해서 사용자에게 반환토록 하였다. 다음은 LLM에게 같이 넘겼던 프롬프트이다. 참고하고 구현에 도움이 되었으면 좋겠다.
export function promptRAG(
question: string,
documents: {
diary_id: number;
memberId: string;
sentence: string;
date: string;
}[],
today: string,
) {
const formattedDocs = JSON.stringify(documents, null, 2);
return `
사용자의 질의는 다음과 같습니다:
질문: "${question}"
오늘 날짜는 ${today}입니다.
사용자의 질문에 "최근", "3개월 이내", "작년", "저번달", "2주전" 등 기간을 포함하는 표현이 있다면, 반드시 문장의 날짜(date 필드)를 보고 비교해서 판단해 주세요.
아래는 과거에 사용자가 작성한 일기 문장들입니다.
각 문장에는 다음 필드가 포함되어 있습니다:
- diary_id: 해당 문장이 포함된 일기의 고유 ID
- sentence: 일기 문장 내용
- date: 문장이 작성된 날짜 (YYYY-MM-DD 형식)
또한, 문장에는 다음과 같이 전처리를 위한 태그가 붙어있을 수 있습니다.
예시 : [tag] sentence
위 질문에 대한 검색으로 다음 문장 목록들이 유효한지 검사해주세요. 태그가 일치하다면 큰 가점을 주면 좋습니다.
유효하다면 true, 아니라면 false, 결과를 JSON 배열 형식으로 반환해 주세요.
json 외의 다른 설명은 하지 말고 출력하세요
문장 목록:
${formattedDocs}
응답 형식 (주의: JSON 배열만 반환하세요):
[
{
"diary_id": 76,
"sentence" : "이러한 일이 있었다"
"is_similar": true
},
{
"diary_id": 92,
"sentence" : "저러한 일이 있었다"
"is_similar": true
},
{
"diary_id": 84,
"sentence" : "그러한 일이 있었다"
"is_similar": false
}
]
`;
}사실 위에서 적었던 구현 외에도 태그 라벨링 등 여러 장치를 도입해보았는데, 정말 이 때문에 정밀도가 올라갔는지는 확신이 서지 않아 따로 적지는 않았다. 찾으면 찾을수록 굉장히 다양한 임베딩 모델들이 있는 것을 알게 되었고, 이들을 하나하나 다 써보고 어느 것이 가장 좋을지도 확인하는 중이다.
'NestJS' 카테고리의 다른 글
| NestJS + Qdrant 사용해보자 !! (6) | 2025.08.08 |
|---|---|
| AWS bedrock 사용기 (5) | 2025.08.05 |
| 반환 정보 편집하기 (1) | 2025.06.15 |
| 입력 정보 검증하기 (0) | 2025.06.15 |
| TypeORM 간단 사용법 (0) | 2025.06.15 |