
면접을 볼 때 JVM 튜닝을 해 보았냐는 질문을 받았다.
당연히 해본적 없다. 튜닝을 해야 할 만큼 뭔가 트래픽이 들어와 본적도 없고, 최후의 수단으로만 사용하는 방법이라고 알고 있기 때문이다.
하지만 트래픽이 생기지 않았다고 해서 경험하지 않으면 결국 영원히 건드리지도 못할 것 같아서 조금 해보기로 했다.
거기에 겸사로 OOM(Out Of Memory)이 발생했을 때의 로그를 어떻게 보면 될지도 조금 공부했다.
G1GC 기준이다.
실험
실험 대상 코드
import java.util.ArrayList;
import java.util.List;
public class GCLearning {
// 메모리 누수를 일으킬 정적 리스트 (GC 대상이 되지 않음)
static List<byte[]> leakList = new ArrayList<>();
public static void main(String[] args) throws InterruptedException {
System.out.println("=== JVM GC Lab Started ===");
int loopCount = 0;
while (true) {
// 1. Young Gen 부하 주기 (짧은 생명주기의 객체 대량 생성)
for (int i = 0; i < 1000; i++) {
byte[] tmp = new byte[1024]; // 1KB (바로 버려짐)
}
// 2. Old Gen 부하 주기 (메모리 누수 시뮬레이션)
// 10MB씩 힙 메모리에 영구 저장
if (loopCount % 100 == 0) {
leakList.add(new byte[1024 * 1024 * 10]); // 10MB
System.out.println("Current Leaked Data: " + (leakList.size() * 10) + " MB");
}
loopCount++;
Thread.sleep(5);
}
}
}코드를 보면 무한히 실행되는 while 문 내에서 1KB 짜리 데이터들을 1000번 만들고 있다. 이 데이터들은 다른 객체를 통해 도달하지 못하므로 Mark and Copy을 통해 Minor GC를 맞으면 금방 사라질 것이다.
그 다음, loopCount가 100단위로 떨어질때마다 10MB짜리 데이터를 leakList에 추가한다. G1GC 정책에서는 각 데이터들을 1MB짜리 블록에 추가하는데, 이 크기를 초과하면 특별 관리 구역에 집어넣는다. 그리고 이 영역은 Old 영역으로 간주된다.
( G1GC 정책은 JDK 9+ 부터 기본 정책이다 )
그리고 메모리가 꽉 차기 시작하면 Major GC를 시작하는데, 10MB짜리 데이터들은 leakList를 통해 '도달 가능한' 객체들이다.
따라서 Major GC에서도 쓰레기값으로 판단되지 않으므로, 지워지지 않는다.
마지막으로는 OOM이 발생하며 애플리케이션이 죽을 것이고, 이 때의 로그를 한번 분석하고, 그래픽으로도 보자.
javac GCLearning.java위 코드를 컴파일한다.
첫번째 실험 : Minor GC와 Major GC
java -Xms256m -Xmx256m -Xlog:gc* GCLearning- -Xms : 초기 힙 크기 설정 (256m -> 256MB)
- -Xmx : 최대 힙 크기 설정
- -Xlog:gc* : gc 태그를 포함한 모든 로그를 확인한다
JVM 튜닝의 기본은 초기 힙 크기와 최대 힙 크기를 같도록 해 주는것이다. 초기 힙 크기를 최대 힙 크기보다 작게 해두면 OOM이 발생할 때마다 힙을 더 할당받게 되고, 이는 또 오버헤드로 이어지게 된다. 위처럼 힙 크기를 설정해두지 않으면 기본적으로 최대 힙 크기는 인스턴스(컴퓨터) 물리 메모리의 1/4를 사용하고, 초기 힙 크기는 1/64를 사용하게 된다.
여기서 주의해야 할 점은 요새는 컨테이너로 jvm 애플리케이션을 많이 사용하는데, 이 때는 이 컨테이너에 할당된 메모리를 물리 메모리로 인식한다. 따라서 도커파일을 만들 때 다음과 같이 퍼센테이지로 힙 크기를 조절하는 것이 좋다.
(그런데 보통 도커 컨테이너의 기본 메모리 크기가 인스턴스의 메모리 크기와 같기 때문에 안해도 될듯??)
ENTRYPOINT ["java", "-XX:MaxRAMPercentage=75.0", "-XX:InitialRAMPercentage=75.0", "-jar", "app.jar"]이러면 초기와 최대 힙 크기가 물리 메모리의 75퍼센트를 사용한다는 의미이다.
그럼 일단 위의 명령어를 실행한 후 로그를 보자.
[0.420s][info][gc ] GC(1) Pause Young (Normal) (G1 Evacuation Pause) 50M->11M(256M) 4.508ms시작한지 얼마 안되어 위와 같은 로그를 볼 수 있다. Pause Young은 Minor GC가 발생했다는 의미이며, GC가 발생한 후 50MB를 차지하던 메모리 공간이 11M으로 줄어들었다는 의미이다. 그리고 마지막의 시간은 GC동안 발생한 stop the world(또는 copy)의 시간이다.
[11.102s][info][gc ] GC(20) Pause Young (Concurrent Start) (G1 Humongous Allocation) 210M->209M(256M) 5.489ms이렇게 G1 Humongous Allocation 이 뜨는 건 10MB 짜리 객체를 생성할 때 이를 Humongous 구역에 할당하겠다는 의미이다. 이런 로그가 자주 발견된다면, 코드 단위에서의 수정 또는 Heap Region Size를 튜닝해야 한다.
- -XX:G1HeapRegionSize=N : HeapRegion의 사이즈를 N으로 조절한다. 이때 N은 2의 거듭제곱이 되어야 하고, 최소 1MB에서 32MB 사이즈여야 한다.
하지만 마냥 크게 잡으면 트레이드오프가 있기 때문에 주의해야 한다. Region 사이즈가 크다면 내부 단편화나 GC의 시간이 지연될 수 있다. 코드 단위에서의 수정이 가장 좋을거 같다. JVM의 튜닝은 항상 최후의 수단이다.
그리고 계속 leakList에 객체가 추가되면...
[13.423s][info][gc ] GC(31) Pause Full (G1 Compaction Pause) 253M->253M(256M) 6.156ms이렇게 Major GC가 발생하게 된다. 하지만 정리되는 메모리가 하나도 없다 !! 위에서도 봤듯이 지금 메모리를 차지하는 대부분의 객체들은 모두 leakList를 통해 도달 가능하기 때문에 GC의 대상이 되지 않는 것이다. 모든 객체를 뒤져봤으므로 당연히 Minor GC보다 시간도 오래 걸리게 된다. 이 Major GC가 자주 발생하지 않도록 하는 것이 핵심이다.
이 상태가 지속되면...
java.lang.OutOfMemoryError: Java heap space
at GCLearning.main(GCLearning.java:21)이렇게 OOM이 뜨면서 죽어버리게 된다.
당연히 처음에서 힙 크기를 크게 주면 OOM이 더 늦게 걸릴 것이다. 그러면 왜 죽었는지 알고 싶은데 어떻게 하면 될까?
두번째 실험
java -Xms256m -Xmx256m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./heapdump.hprof GCLearning- -XX:+HeapDumpOnOutOfMemoryError : OOM으로 애플리케이션이 죽을 때 dump 파일을 생성
- -XX:HeapDumpPath : dump 파일을 생성할 경로를 지정
이제 dump 파일이 생성된 것을 확인하고 이를 열어보자. IntelliJ 에서 바로 열 수 있다.

이렇게 가장 큰 객체가 무엇인지 친절히 알려준다. 나는 한글 플러그인을 사용 중이라 이상하게 번역 되는데 얕음은 shallow, 유지는 retained으로 보면 된다.
shallow size는 객체 본연의 사이즈, retained는 이 객체가 붙들고 있으며 이 객체를 통해 도달 가능한 객체들의 총 사이즈를 말한다. 즉 이 객체가 사라지면 GC의 대상이 될 객체들의 사이즈이다.
로그 파일이나 로그를 직접 https://gceasy.io/gc-dashboard.jsp 이 사이트에 넣으면 분석도 해준다.
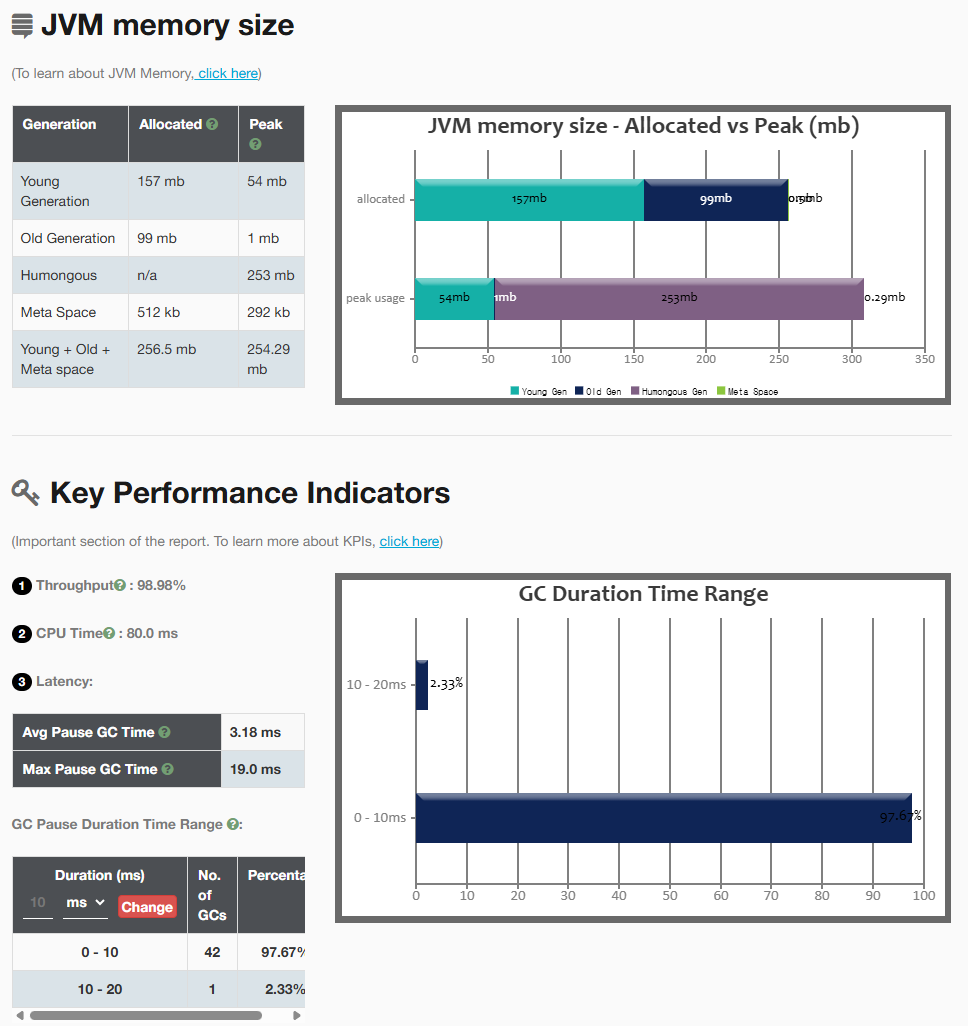
여기서 친절하게 평균 GC 타임과 최장 GC 타임도 분석해준다. 이제 이 사이트를 이용해서 다른 정책과 G1GC의 GC 타임을 비교해보자.
세번째 실험
java -Xms256m -Xmx256m -XX:+UseSerialGC -Xlog:gc* GCLearning같은 힙 크기에서 SerialGC를 사용해서 로그를 한번 분석해보자.
이 GC는 단일 스레드로 GC를 수행하기 때문에 메모리 사용량이 적어서 초기 컴퓨터에서 굉장히 유용히 사용되었다. JDK 1~4 까지 사용되었다고 한다.

평균 GC 시간이 G1GC의 3ms에서 확 늘었다.
여기서 알수 있는 튜닝 포인트는 대개 G1GC가 훨씬 좋지만, 만약 메모리가 매우 부족한 환경이라면 SerialGC를 사용하도록 튜닝하는 것이 좋다는 것이다. 음 예를들면... GCP나 오라클에서 제공하는 메모리 1GB짜리 무료 인스턴스를 사용할 때? 그때는 GC 자체가 먹는 메모리도 부담스러울 테니까
'Java' 카테고리의 다른 글
| 자바 가비지 컬렉터 (GC) (0) | 2025.09.07 |
|---|---|
| JVM (0) | 2025.09.06 |
| SOLID 원칙 (0) | 2025.09.05 |
| 와일드카드<?>가 무엇인가? (0) | 2025.08.23 |
| Supplier는 왜 쓰는걸까? (0) | 2025.08.16 |